Is This How Science Dies?
All the "disruption" may have broken science's troth with society
Recently, the Director of the Department of Health and Human Services, Xavier Becerra, was quoted in the Washington Post, saying:
I can’t go toe to toe with social media. I don’t get to write whatever I want.
A major change in how social media works — what Patreon CEO Jack Conte describes as a shift from “follow culture to feed culture,” where instead of users preferentially seeing things they follow to users seeing what an algorithm feeds them — hasn’t helped the cause of science-based policies. Now, whatever drives clicks and time on site rules.
Feeds prefer misinformation — the more frightening and outrageous, the better. And now that Meta has pulled the plug on its anti-misinformation systems — which they once claimed were 90% effective at eliminating scams and lies — things are only going to go from bad to terrible.
Meta isn’t the only one. Google was key to spreading the first vaccines-autism conspiracy theory. Now, Google Scholar has become a major source of misinformation, with fake AI-generated scientific articles flooding the search engine. One study’s findings of AI-fabricated junk science shows that fake science has been made available and can be spread widely and at low cost by malicious actors.
Recent coverage summarizes the implications in the following way:
The researchers behind the study have already seen that these problematic articles have spread to other parts of the research infrastructure on the web, in various archives, social media, and the like. The spread is fast and Google Scholar makes the problematic articles visible. Even if the articles are withdrawn, there is a risk that they have already had time to spread and continue to do so.
One author notes:
. . . Google Scholar is not an academic database. The search engine is easy to use and fast yet lacks quality assurance procedures.
No kidding. You mean a handful of inexperienced people with cyberlibertarian instincts and more vainglory than seriousness haven’t built reliable tech for discovering scientific information? I’m shocked.
Yet, in an example of how lies can get halfway around the globe before the truth has laced up its sneakers, I covered this paper two days after it appeared, while it took Phys.org nearly four months to get to it.
- This is a negative trend I keep seeing — science journalists who are slow to the punch. Good for my subscriptions, bad for timely awareness to broader audiences.
- I’ve covered the noted problem with retractions recently, as well.
Another example making the rounds of what is becoming called “zombie facts” relates to black plastic cooking utensils, where a study claiming they posed an imminent danger was found to include a major mathematical error, throwing off estimates by an order of magnitude. A correction was issued, but the urban legend has been established and is circulating widely.
A similar thing happened with a preprint about Covid-19 vaccines, where Canadian physicians estimated the cardiovascular risk of vaccines, but made a major math error. They withdrew the preprint, but the damage was done, as conspiracy theorists had already whipped up their audiences about the false risk.
In a forthcoming report from the National Academy of Sciences (PDF link at bottom), the authors find there are a few sources of misinformation coming directly out of the scientific establishment:
- Hype, which can be aided and abetted by university press offices and others seeking media coverage, including authors themselves
- Biases or distortions in the analysis, interpretation, presentation, and/or publishing of scientific data
- Preprints
The authors write about the latter:
A third way that misinformation about science can emerge from within the scientific community is through preprints. . . . Research articles posted on preprint archives before they’ve been vetted through a peer review process . . . can both result in low quality and, at worst, deceptive and misleading scientific information circulating in the public domain.
We can see a few of these trends in one recent example, where Bioxytran — a struggling drug development company — posted an article using AI writing to boast about an upcoming preprint.
- The article was posted on January 12th, but the preprint was released on January 10th, so the AI missed its deadline.
The preprint was posted on ResearchGate, and led to media coverage and a bounce back for its beleaguered stock (the deep crevice is January 3rd, or a week prior):
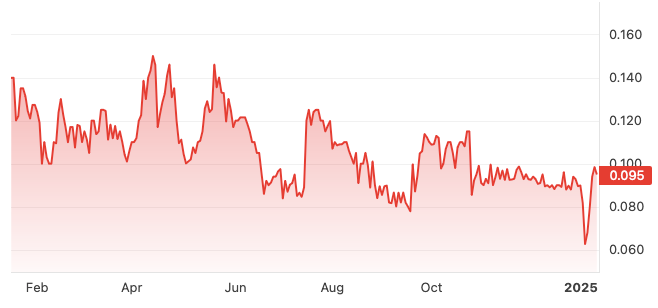
This may be the vaunted “dead cat bounce” of a doomed company’s stock, but once again preprinting is being used as corporate PR. So, here we have:
- Hype
- Biases or distortions (the authors of the preprint are the company’s Chief Medical Officer, the company’s CEO and Chairman, and a company finance or business development person)
- Preprinting
- AI
Lovely.
What is the upshot of all this? Does it matter? Or is the public too smart to fall for these things, and too protected by OA articles to believe hoaxes and charlatans?
Well, here are what the data show:
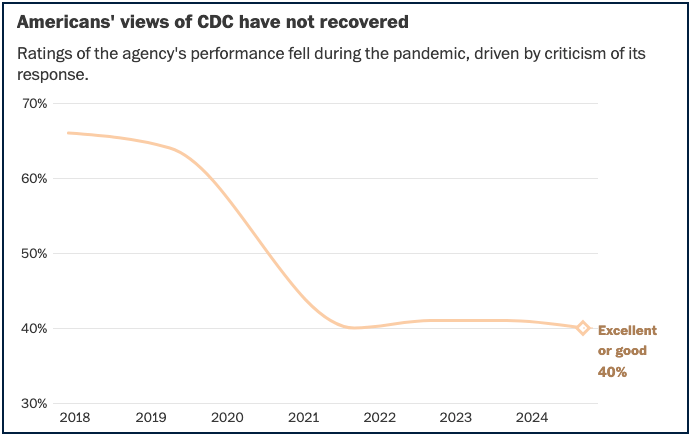
- Faith in public health officials is below 50%.
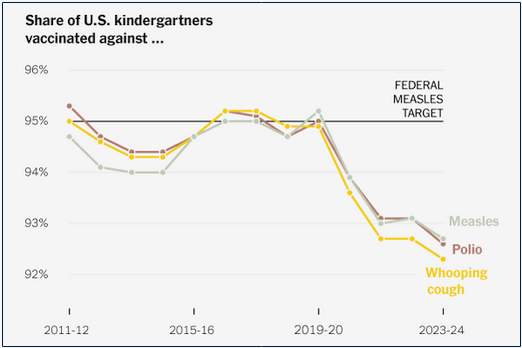
- Vaccines among children have fallen below the levels needed to be truly effective at a population level.
So, more information is not helping us. Bad discovery tools on top of this aren’t helping. New information tech that creates plausible but false and misleading information isn’t helping us.
Basically, we’re on the wrong path.
Yuval Noah Harari discussed views of how information works in his latest book, Nexus: A Brief History of Information Networks from the Stone Age to AI, writing:
The naive view argues that by gathering and processing much more information than individuals can, big networks achieve a better understanding of medicine, physics, economics, and numerous other fields, which makes the network not only powerful but also wise. . . . This view posits that in sufficient quantities information leads to truth, and truth in turn leads to both power and wisdom. . . . the naive view assumes that the antidote to most problems we encounter in gathering and processing information is gathering and processing even more information. . . . This naive view justifies the pursuit of ever more powerful information technologies and has been the semiofficial ideology of the computer age and the internet. . . . this book strongly disagrees with the naive view.
It’s time to stop being so naive. Conflicted OA business models, preprints that make a mockery of expert review, sloppy search indexing, low standards, pay-to-play publishing, and layers of crappy tech stacked one atop another — none of it is working to help society move forward, be safer, or be healthier.
It’s time for a major course correction.